正观新闻2024年11月18日发布澳彩机密六码中特: 两位本科生一作,首次提出「持续学习」+「少样本」知识图谱补全 CIKM 2024
作者:唐一菲 | 责任编辑: Admin
本文点赞(57) | 阅读:(34)
| 【新澳新澳门正版资料】 | 【新澳正版资料免费大全】 | 【2024新澳门精准免费大全】 | 【新奥精准免费资料提供】 | 【2024新澳精准正版资料】 | 【2024新澳正版资料最新更新】 | 【2024年天天彩免费资料】 | 【2024澳门精准正版免费大全】 | 【2024新澳精准资料大全】 | 【2024新澳正版免费资料大全】 |

新智元报道
编辑:LRST
【新智元导读】上海大学本科生研发的新框架能有效应对知识图谱补全中的灾难性遗忘和少样本学习难题,提升模型在动态环境和数据稀缺场景下的应用能力。这项研究不仅推动了领域发展,也为实际应用提供了宝贵参考。
知识图谱(Knowledge Graphs)是一种结构化的,用于展示和管理信息,组织现实世界知识的形式。其通常被表达为三元组形式(<头实体,关系,尾实体>)。KGs 为问答系统、推荐系统和搜索引擎等各种实际应用提供了极其重要支持。
然而现有知识图谱的显著不完整性严重限制了其在实际应用中的有效性。
同时,在现实实际应用中,知识图谱中的关系呈现长尾分布,即大多数关系只有少量相关的三元组。这种稀缺导致了模型对于长尾关系的泛化能力不足,从而使得知识图谱补全模型的整体效果较差 (Few-shot Learning) 。
进一步,随着时间的推演,越来越多的新关系被添加到关系集中,并在不同时间点集成到知识图谱中。这意味着模型不仅需要学习当前阶段的知识更需要记住在之前阶段学习过的知识 (Continual Learning) 。
最近,上海大学的本科生李卓风、张灏翔(第一作者以及共同第一作者)在信息检索和数据挖掘领域顶级学术会议CIKM 2024上发表了一篇文章,首次提出了在持续学习 (Continual Learning) 和少样本 (Few-shot) 的场景下对知识图谱进行补全,提供了一套全面且有效的框架来处理这一问题。

论文标题:Learning from Novel Knowledge: Continual Few-shot Knowledge Graph Completion
代码链接:https://github.com/cfkgc-paper/CFKGC-paper/tree/main
该研究的发表将有助于提高知识图谱补全(KGC)模型在实际应用中的泛化能力,使其能够更好地适应动态环境和数据稀缺的场景,从而推动相关领域的应用发展。
通过提供有效的解决方案,本研究为后续研究奠定了基础,同时也为实际应用提供了重要的参考。
研究背景
目前在持续学习 (Continual Learning) 和少样本 (Few-shot) 的场景下对知识图谱进行补全面临两大挑战:
1. 灾难性遗忘问题,即模型在不断学习新关系时,对之前学到的关系的推理性能下降。这会导致模型退化和对稀有关系的推断能力大幅减弱。
2. 新关系的稀缺导致模型在稀有关系上的泛化能力不足。
为解决这些挑战,该研究提出了一个完整且有效的知识图谱补全框架,以适应不断出现的少量的关系。
1. 为了 解决灾难性遗忘问题,研究人员从数据和模型两个维度入手。
2. 为了解决 关系的稀缺导致模型在稀有关系上的泛化能力不足的问题,研究人员引入了一种多视角关系增强技术。该方法通过自监督学习提升模型的泛化能力。
技术方法
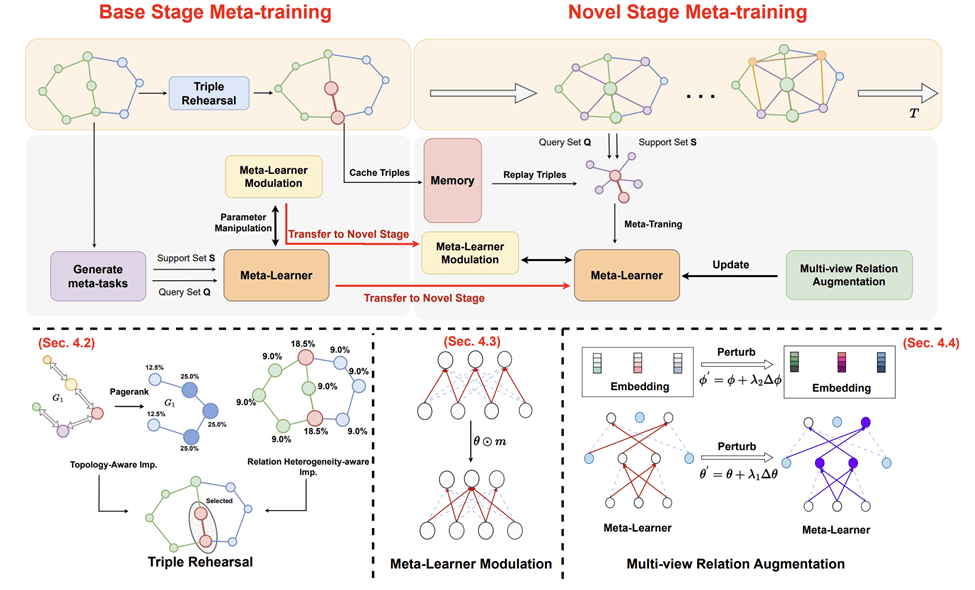
三元组的记忆回放
为了缓解灾难性遗忘问题,研究人员从数据和模型两个层面提出了解决方案。在数据层面,通过特别设计的指标来评估每个实体的重要性,并在内存中存储最重要的三元组。
这些缓存的三元组可以在新关系出现时进行重播,以确保模型能够回忆起最重要的知识。
具体来说,从两个角度评估实体的重要程度:
1. 拓扑感知重要度。在知识图谱中,一个实体的重要性应当由与其相连的其他实体的重要性共同决定。
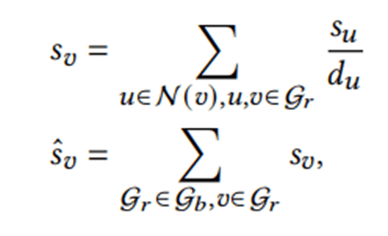
其中du表示实体u的出边数量,N(v)表示实体v在Gr中的邻居集合。
是实体v的最终拓扑感知重要性得分。
2. 除了拓扑结构外,还考虑了实体 参与关系的多样性,即关系异质性感知重要度:
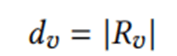
其中|Rv|表示实体v连接的不同关系数量。
最终,可以计算三元组的重要性分数:
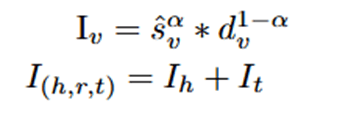
元学习器的调制
文中进一步在模型层面实施了参数调制策略来保存最重要的参数。
具体来说,首先使用权重分数s来衡量网络参数的重要性:
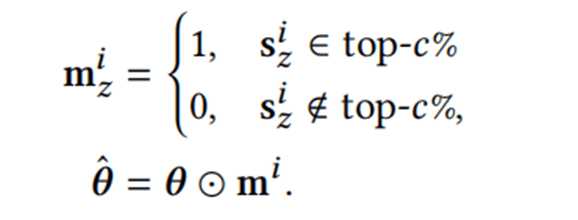
然后,通过下面的优化公式来更新模型参数:
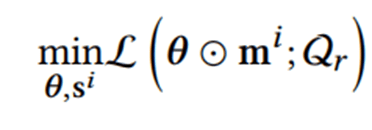
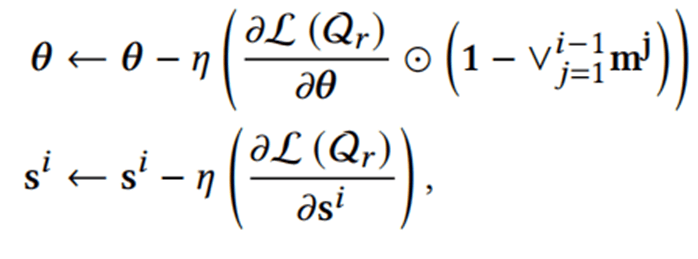
θ是元学习器参数,Qr代表关系集,
是学习率,
通过这种参数调制机制,可以在学习新任务时保护已获得的重要知识,从而有效缓解灾难性遗忘问题。
增强少样本和自监督学习
通过引入基于自监督的多视图关系增强技术来增强模型的泛化能力,通过两种扰动方式生成关系的不同视图。
1. 元学习器参数扰动:
2. 输入实体嵌入扰动:
然后通过对比学习损失来优化:
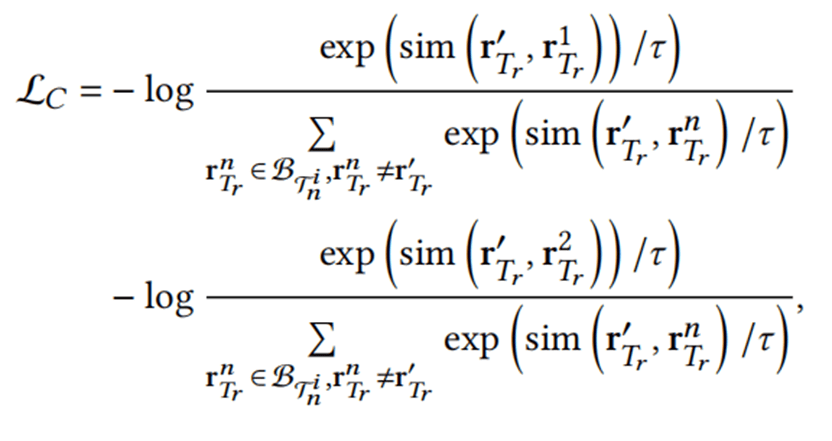
其中τ是温度参数,
一个 Batch 之内的关系集。
与
分别代表经过1或者2扰动之后生成的关系。
实验结果
研究人员在 NELL-ONE 和 Wiki-ONE 两个数据集上对模型进行持续学习以及小样本学习的全面验证。
持续学习能力
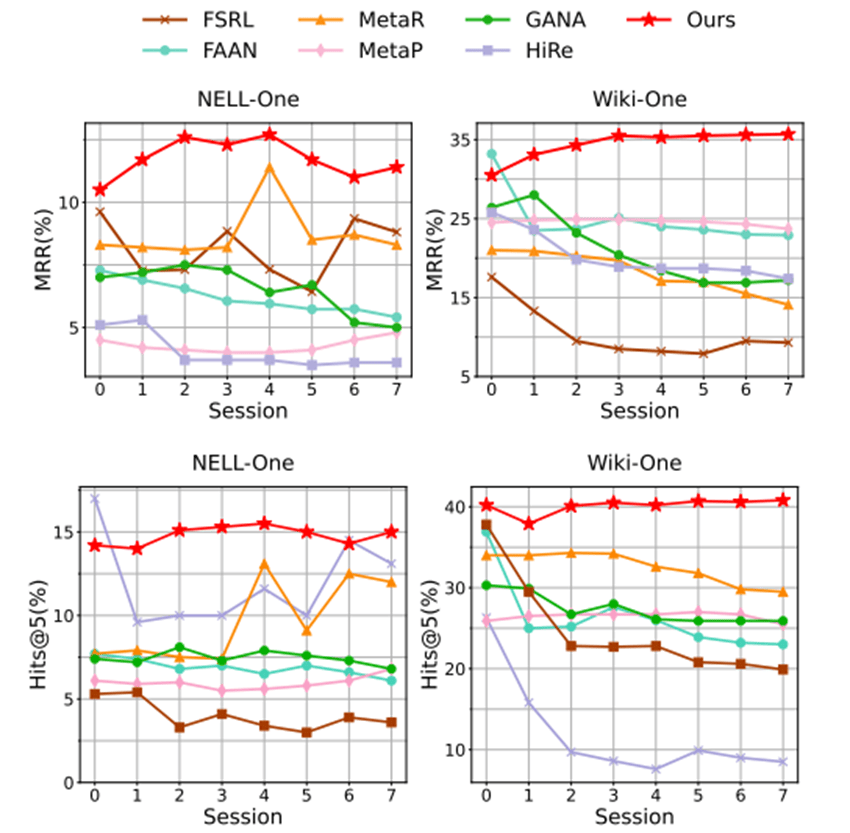
该框架在持续学习方面的表现,与基线模型相比,能够显著减轻灾难性遗忘,且该模型不仅能有效保留先前会话的知识,还在后续会话中表现出更好的性能。该框架相对于基线模型,在减轻灾难性遗忘方面显示出显著优势。

例如,在NELL-One数据集中,方法在后续任务(Task1至Task7)中,平均比第二佳的基线方法改进了+13.3%,而在Wiki-One数据集中,平均改进为+27.0%。这表明该模型不仅有效地保留了之前学习会话的知识,还在随后的学习任务中展示了更优越的性能。
少样本学习能力
在快速适应新的学习进程中的未见关系时,模型能够维持稳定或增强的少样本学习性能。
相反,基线模型由于每个新会话中元任务数量有限,表现出明显的性能下降。这进一步证明了提出的多视角关系增强策略在解决与元任务稀缺相关的过拟合问题中的有效性。
模型在少样本学习方面显示了出色的性能,特别是在快速适应未见关系的新学习环境中。
以NELL-One数据集为例,MRR指标相较于第一个task(11.1%),模型在最后一个任务中表现出11.35%的性能,期间最高达到12.55%。
在Wiki-One数据集中,从基线的38.9%提高到了最后一个任务的40.05%,相对于其他的方法——随着更新的知识的学习,小样本性能也在下降,模型实现了对于更好的小样本学习性能的保持。
结果验证了所提出的多视角关系增强策略在缓解元任务稀缺导致的过拟合问题上的高效性。
结果表明模型不仅可以充分记住先前阶段的知识同时还可以有效学习新的知识。
消融实验
总结
本篇文章探讨了在持续学习以及少量样本的场景下对知识图谱补全的问题,提出了一种全面且有效的框架,旨在应对灾难性遗忘以及少样本带来的挑战。
该方案包括三元组重演策略,模型参数调制策略,多视角关系增强策略。该研究的发表将有助于提高知识图谱补全(KGC)模型在实际应用中的泛化能力,使其能够更好地适应动态环境和数据稀缺的场景,从而推动相关领域的应用发展。
通过提供有效的解决方案,本研究为后续研究奠定了基础,同时也为实际应用提供了重要的参考。
参考资料:返回搜狐,查看更多
责任编辑:
| 【新澳全年免费资料大全】 | 【2024新奥正版资料免费】 | 【2024新澳精准资料免费】 | 【2024新澳资料大全免费】 | 【2024正版资料免费公开】 | 【新澳精准资料免费提供网】 | 【新奥天天精准资料大全】 | 【新奥长期免费资料大全】 |
推荐文章
中俄举行战略安全磋商
1分钟前:2....
接虞书欣丁禹兮三搭
8分钟前:1....
中金岭南接待4家机构调研,包括广东省国资委、深圳证券交易所、广东上市公司协会等嫁大21岁的二婚马景涛,10年生2子被抛弃,41岁的吴佳尼如今怎样了
9分钟前:该研究的发表将有助于提高知识图谱补全(KGC)模型在实际应用中的泛化能力,使其能够更好地适应动态环境和数据稀缺的场景,从而推动相关领域的应用发展。...
品案 六神磊磊炮轰拼多多盗版 北大教授:平台治理问题
6分钟前:灾难性遗忘问题,即模型在不断学习新关系时,对之前学到的关系的推理性能下降。...
最新评论
但如天 2024-11-17 23:16
2.
IP:38.28.1.*
帕翠西亚·希顿 2024-11-17 18:21
同时,在现实实际应用中,知识图谱中的关系呈现长尾分布,即大多数关系只有少量相关的三元组。
IP:82.40.8.*
Bair 2024-11-17 16:22
总结
IP:88.57.4.*